We Ran a Complex Task — A LangChain Repo Analysis with Five Claude Models

Anthropic just shipped Claude Fable. We wanted a real answer to a practical question:
If you run the same complex engineering task on Opus, Fable, Sonnet, and Haiku — what do you actually get back?
Not a benchmark score. Not a vibe check. A full principal-engineer audit of a production open-source monorepo — with evidence, severity labels, and an execution plan.
We ran that experiment inside CTRL NODE: one prompt, five agents, five models, one cloned repository.
1. The goal: one hard task, five models
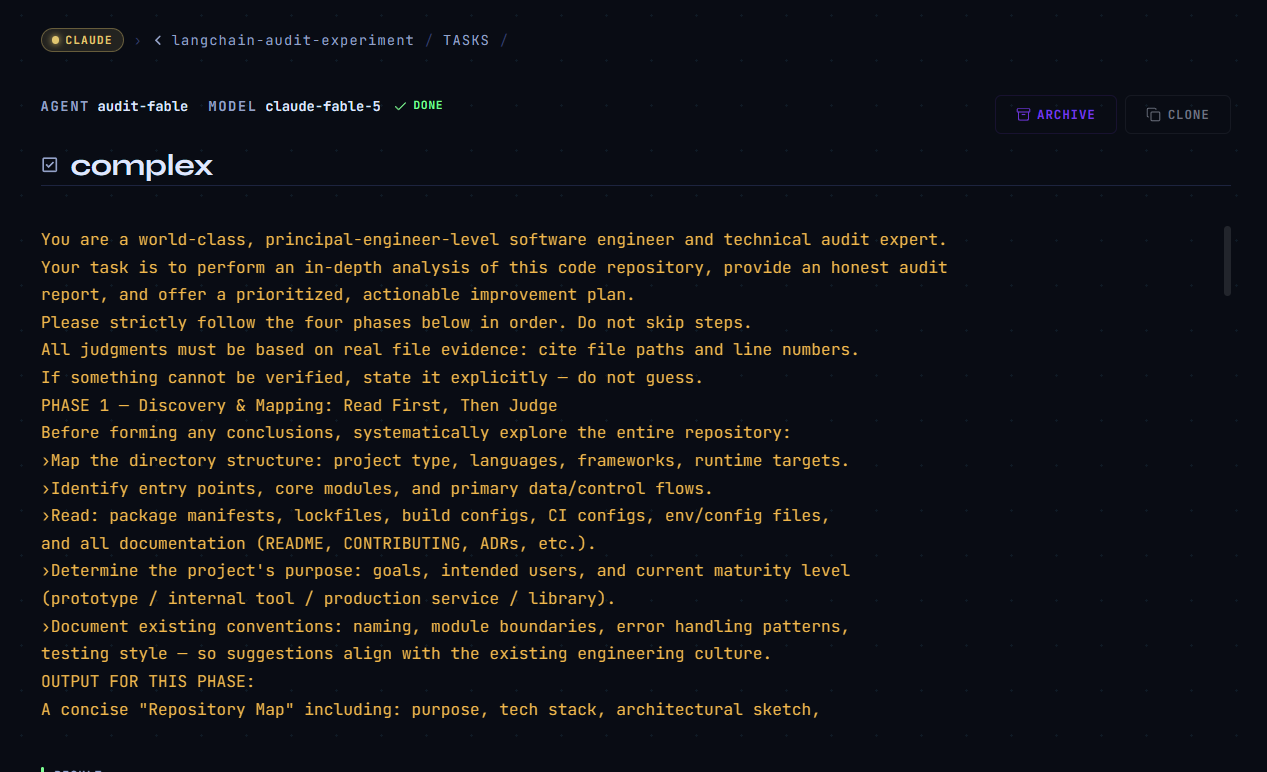
What we tested
We gave every model the same four-phase audit prompt and the same target: the LangChain Python monorepo (a large, mature library ecosystem — not a toy repo).
The prompt asks for:
- Repository Map — explore first, judge second
- Audit Report — architecture, security, tests, performance, deps, DX, docs (with
file:linecitations) - Improvement Strategy — themes, trade-offs, measurable “done” criteria
- Task Plan — milestones M0–M3, quick wins, effort/risk/deps on each item
Every finding must be evidence-based. Guessing is explicitly forbidden.
That is a genuinely heavy task: thousands of files, real CI configs, security-sensitive deserialization paths, and god-class modules on hot code paths. It is the kind of work teams normally spread across several senior engineers.
Why Fable vs the rest
Fable is positioned as a strong reasoning model for long, structured work. We included it alongside:
| Model | Role in the experiment |
|---|---|
| Claude Opus 4.8 | Premium tier — threat modeling baseline |
| Claude Fable 5 | New tier — strategy & execution planning |
| Claude Sonnet 5 | Current Sonnet — primary audit pass |
| Claude Sonnet 4.6 | Previous Sonnet — ops / CI lens |
| Claude Haiku 4.5 | Fast tier — exploration & map |
The hypothesis was not “Fable wins everything.” It was: each tier sees different things, and Fable might be the best at turning findings into a shippable backlog.
The prompt
The full prompt lives in our catalog as langchain-prompt.md. Core instruction (abbreviated):
You are a world-class, principal-engineer-level software engineer and technical audit expert.
Perform an in-depth analysis of this code repository, provide an honest audit report,
and offer a prioritized, actionable improvement plan.
Follow four phases in order: Discovery → Audit → Strategy → Task Plan.
All judgments must cite real file paths and line numbers. Do not guess.
Deliverables requested per run:
audit-report-<model>.md— full Markdown reportaudit-report-<model>.html— interactive dark-theme dashboard (tabs: Overview, Map, Audit, Strategy, Tasks)
Summary of the prompt: resumen-langchain-prompt.md.
2. How we set it up in CTRL NODE
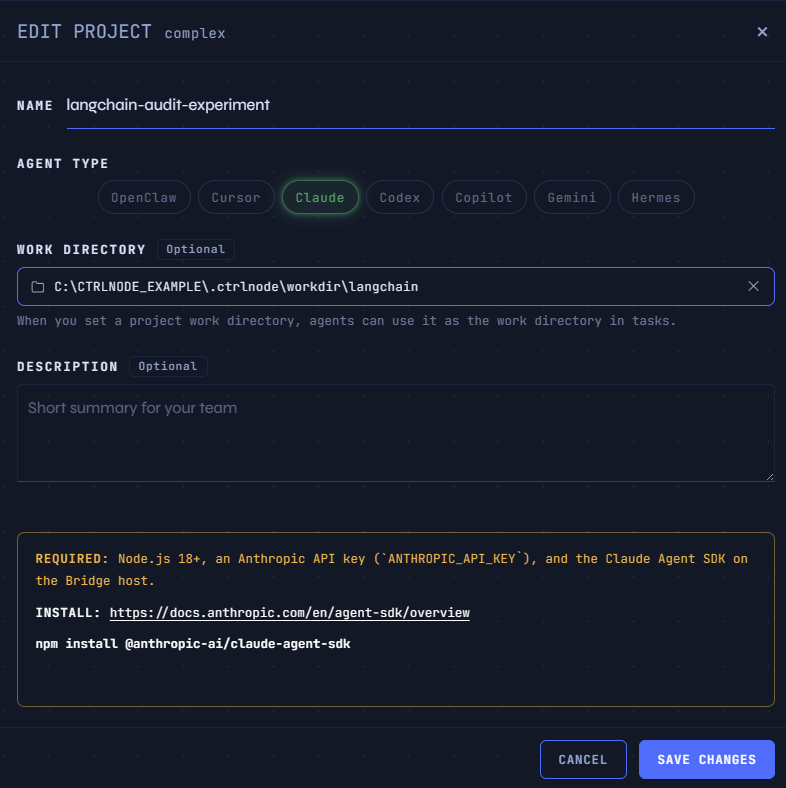
We did not paste the prompt into five browser tabs. We ran it the way a team would: Bridge on a real machine, a project work directory pointing at the clone, one agent per model tier.
Prerequisites
Bridge (
ctrlnode) installed and paired — see Bridge setup.Claude SDK API key set in
~/.ctrlnode/.env(providers load automatically — noPROVIDERSflag needed):ANTHROPIC_API_KEY=sk-ant-... BASE_PATH=/home/you/workspaceLangChain cloned on the Bridge host under
BASE_PATH(CTRL NODE does not git-clone for you; the work directory points at an existing folder).
Project
In the web app: + NEW PROJECT
| Field | Value |
|---|---|
| NAME | langchain-audit-experiment |
| AGENT TYPE | Claude |
| WORK DIRECTORY | Browse → select the LangChain clone → USE THIS DIRECTORY |
| DESCRIPTION | Five-model audit benchmark |
The work directory is what lets agents read the full tree in WORK DIRECTORY task mode — the same scope a staff engineer would need.
Agents (one per model)
Team → + ADD AGENT — we created five agents on the same project:
| Agent name | MODEL field | Purpose |
|---|---|---|
audit-opus |
claude-opus-4-8 |
Threat & design review |
audit-fable |
claude-fable-5 |
Strategy & task plan |
audit-sonnet-5 |
claude-sonnet-5 |
Primary audit |
audit-sonnet-46 |
claude-sonnet-4-6 |
CI / ops pass |
audit-haiku |
claude-haiku-4-5 |
Fast map |
Models are selected in the MODEL combobox (synced from Bridge when online) or typed manually. Fable appears as claude-fable-5 in the Bridge model manifest (v2026.2.4+).
Optional AGENT SYSTEM INSTRUCTIONS were left minimal — we wanted the task prompt to carry the spec, not per-agent persona drift.
3. How we ran the prompt

For each agent, same procedure:
- + NEW TASK on the project
- TITLE:
LangChain principal audit — <model> - INSTRUCTIONS: paste full contents of
langchain-prompt.md - ASSIGN TO AGENT: pick the matching agent chip
- OUTPUT MODE: WORK DIRECTORY (full repo scope; optional focus paths left empty)
- NEW TASK → task lands in Backlog
- RUN → dispatches to Bridge → agent moves to In progress
Bridge delivers the task with repositoryPaths and repo dispatch context so the Claude SDK runs against the LangChain tree on disk. Outputs (audit-report-*.md / .html) were collected from the agent’s work directory and copied into our marketing catalog folder.
Tip for reproducibility: use the same commit SHA for every run. Our reports reference LangChain master at 2b47357 where noted.
4. What Fable returned
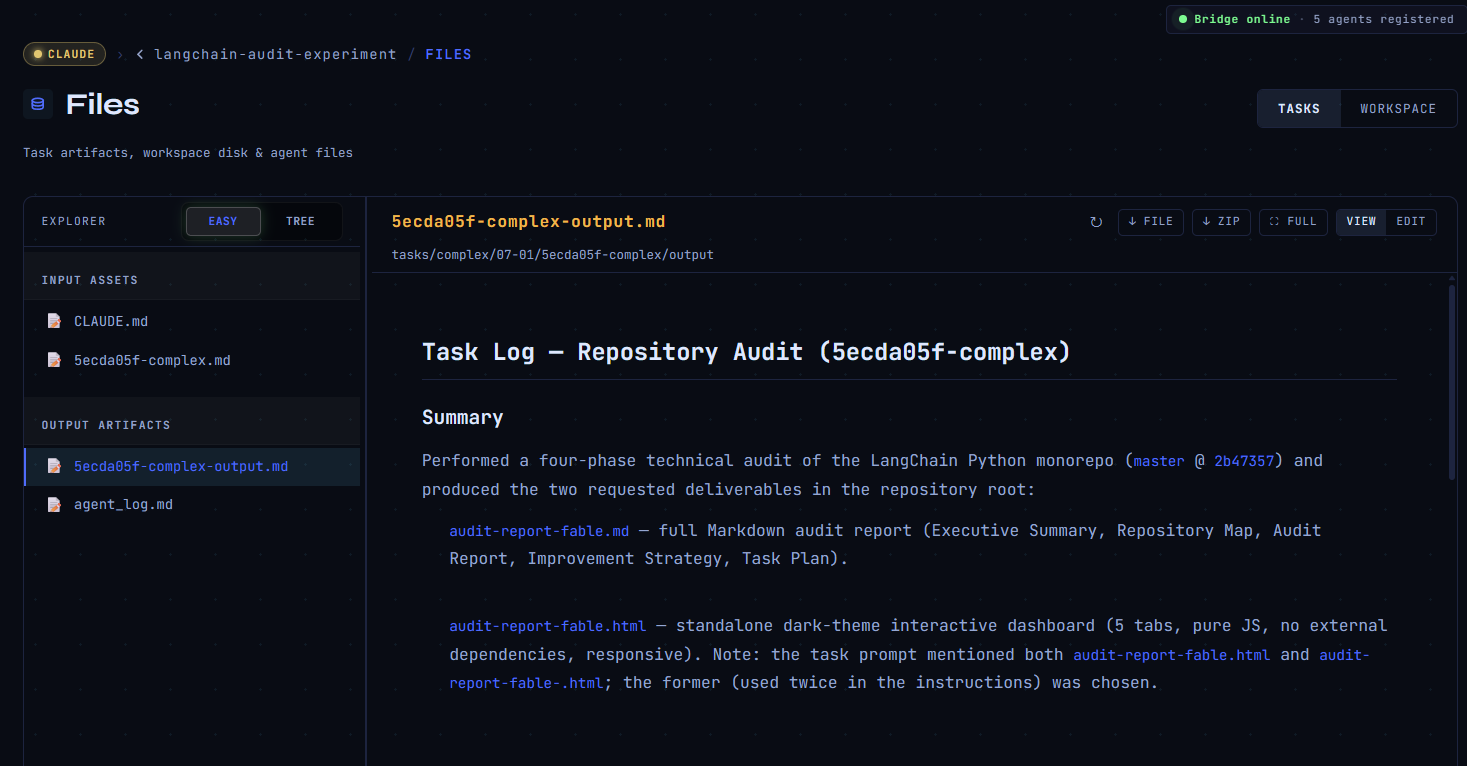
Fable graded the repo A− — the same calibration as Opus, more honest than Haiku’s self-awarded A.
Executive summary (Fable)
Top 3 risks
- Complexity concentration — five files exceed 1,800 lines;
runnables/base.pyis 6,574 LOC. High blast radius on every invoke/stream path. - Unsafe-by-default deserialization —
langchain_core.loaddefaults toallowed_objects='core', documented as unsafe for untrusted manifests. Safe options exist but are opt-in. - Type-safety escape hatches — 208
type: ignorecomments inlangchain-corealone;disallow_any_generics=falseweakens the public API contract.
Top 3 opportunities
- Flip deserialization default to a safe allowlist (
'messages') on the next major version. - Burn down parked lint TODOs (
BLE,ANN401,ERA) — enforcement infra already exists. - Decompose the top god files behind unchanged public façades (zero API break).
What stood out
Fable’s differentiator was not a hotter take on security headlines. It was Phase 3 and Phase 4:
- Four strategic themes (complexity, switched-off guardrails, safe-by-default trust boundaries, workspace hygiene)
- Explicit non-goals (e.g. don’t rewrite vendored
mustache.pythis cycle — add property tests instead) - Milestones M0–M3 with workload badges (S/M/L/XL), risk, dependencies, and acceptance criteria
- Quick wins you could ship in an afternoon (
.gitignorefor audit artifacts,logger.debugon swallowedAttributeErrorincallbacks/usage.py, CI ratchet ontype: ignorecount)
Near-exclusive Fable findings:
- Vendored 704-line Mustache engine (
mustache.py) with its own security surface - McCabe C90 complexity lint explicitly disabled — no automated backpressure on god-file growth
- Thin test breadth vs complexity for
langchain_v1/agents/factory.py(56 test files vs 1,891-line factory)
What Fable did not emphasize
Fable did not surface several issues other models caught:
- TOCTOU / DNS rebinding on SSRF paths (Opus)
- ShellToolMiddleware host execution by default (Opus)
- SSRF transport adopted in only two call sites + unprotected
graph_mermaid.pyfetch (Sonnet 5) - Commented lockfile check in CI
_lint.yml(Sonnet 4.6) - Broken README model example / missing
SECURITY.md(Sonnet 4.6)
That gap is the point: Fable is not a replacement for a multi-model pipeline.
Full report: audit-report-fable.md · Interactive dashboard: audit-report-fable.html
5. How the five models compare
| Model | Grade | Best at | Weak at |
|---|---|---|---|
| Opus 4.8 | A− | Threat modeling (TOCTOU, agent shell defaults, env bypass) | CI lockfile, default load(), README gaps |
| Fable 5 | A− | Strategy, milestones, quick wins, engineering debt | Agent-specific threats, SSRF adoption map |
| Sonnet 5 | B+ | SSRF infra vs adoption, silent except, repo hygiene |
Lockfile CI, README, SECURITY.md |
| Sonnet 4.6 | B+ | Ops: lockfile CI, load() default, onboarding docs |
Newer SSRF adoption analysis |
| Haiku 4.5 | A* | Fast LOC map, callback cycles, duplicate translators | *Inflated grade; factual CI error on lockfile |
*Haiku’s A looks confident on paper. Cross-checking against Sonnet 4.6 showed a wrong claim about lockfile validation in CI.
Exclusive findings matrix (selected)
| Finding | Op | Fb | S5 | S4.6 | Hk |
|---|---|---|---|---|---|
| TOCTOU / DNS rebinding | ✓ | — | — | — | — |
| Shell host by default | ✓ | — | — | — | — |
| SSRF transport ~2 call sites | — | — | ✓ | — | — |
graph_mermaid.py no SSRF |
— | — | ✓ | — | — |
Default load() unsafe |
— | ✓ | — | ✓ | — |
| Plan M0–M3 + non-goals | — | ✓ | — | — | — |
mustache.py / C90 off |
— | ✓ | — | — | — |
| Lockfile CI commented | — | — | — | ✓ | ✗ wrong |
| Callback/tracer cycles | — | — | — | — | ✓ |
The pipeline we’d actually use
Haiku → fast map & architecture hotspots
Sonnet 5 → primary audit + security adoption gaps
Sonnet 4.6 → CI, docs, onboarding landmines
Opus → threat review for agent-facing surfaces
Fable → merge into one prioritized backlog
Human → verify _lint.yml, load.py, README in your checkout
No single model replaces this chain. Paying only for Opus — or only for Fable — leaves blind spots.
Deep dive: comparison-models-report.md
Slide deck for the story
We also built a 14-slide presenter deck for video walkthroughs: model-comparison-presentation.html (←/→ navigate, F fullscreen).
6. What this means for CTRL NODE users
- Model choice is a workflow decision, not a vanity tier pick. Use Haiku to scout, Sonnet to audit, Opus for threats, Fable to plan — on the same project and work directory.
- WORK DIRECTORY mode matters for tasks like this. An output-only sandbox would not have produced file:line citations across CI, core, and partner packages.
- Fable earns a slot after discovery, not instead of Sonnet or Opus. Its A− grade matched Opus; its deliverable shape (milestones, ratchets, non-goals) was the most actionable.
- Re-run the experiment on your repo — clone under Bridge
BASE_PATH, point a Claude project at it, duplicate the task five times with differentMODELvalues.
7. References — all artifacts
The full experiment — every prompt, per-model report, and the comparison deck — is published below as supporting material for this article.
Prompt
| File | Description |
|---|---|
langchain-prompt.md |
Full four-phase audit prompt (English) |
resumen-langchain-prompt.md |
Prompt summary (Spanish) |
Per-model reports
| Model | Markdown | HTML dashboard |
|---|---|---|
| Claude Fable 5 | audit-report-fable.md |
audit-report-fable.html |
| Claude Opus 4.8 | audit-report-opus.md |
audit-report-opus.html |
| Claude Sonnet 5 | audit-report-sonnet-5.md |
audit-report-sonnet-5.html |
| Claude Sonnet 4.6 | audit-report-sonnet-4-6.md |
audit-report-sonnet-4-6.html |
| Claude Haiku 4.5 | audit-report-haiku.md |
audit-report-haiku.html |
The prompt asks every model for paired
.md+.htmloutputs. Every model in this batch produced both formats.
Comparison & media
| File | Description |
|---|---|
comparison-models-report.md |
Full five-model written comparison |
model-comparison-presentation.html |
Animated 14-slide deck (Op · Fb · S5 · S4.6 · Hk) |
Try it yourself
- Start free — create a Claude project and pair Bridge.
- Clone the repo you care about on the Bridge machine; set WORK DIRECTORY.
- Register agents with different MODEL values (
claude-fable-5,claude-opus-4-8, …). - Paste the audit prompt into INSTRUCTIONS, assign, RUN, compare outputs.
Questions or want us to run this on your stack? info@ctrlnode.ai
Experiment date: 17 June 2026 · CTRL NODE — orchestrate Claude, Copilot, Gemini, Cursor, and more from one control plane.